机器学习 | 模型评估与选择之性能度量
性能度量是衡量模型泛化能力的评价标准,反映了任务需求;使用不同的性能度量往往会导致不同的评判结果。
回归任务最常用的性能度量是“均方误差”:
<div align=center>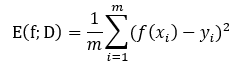 </div>
</div>
一般式子
对于数据分布D和概率密度函数p(.)
均方误差可描述成:
<div align=center></div>
对于分类任务,错误率和精度是最常用的两种性能度量: 错误率:分错的样本占样本总数的比例
错误率:分错的样本占样本总数的比例 精度:分对的样本占样本总数的比例
精度:分对的样本占样本总数的比例
分类错误率:
<div align=center> </div>
</div>
分类精度:
<div align=center>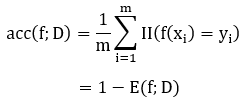 </div>
</div>
一般式子
对于数据分布D和概率密度函数p(.)
分类错误率和分类精度可描述成:
分类错误率:
<div align=center>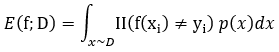 </div>
</div>
分类精度:
<div align=center>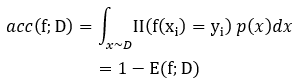 </div>
</div>
查准率和查全率有时候比错误率和精度更适合描述,查准率和查全率是一对矛盾体。 查准率:检索到的数据中有多少比例是用户想要的
查准率:检索到的数据中有多少比例是用户想要的 查全率:用户想要的数据有多少比例被检索出来
查全率:用户想要的数据有多少比例被检索出来
<div align=center>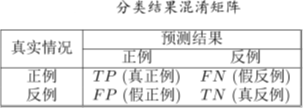 </div>
</div>
查准率:
<div align=center>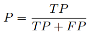 </div>
</div>
查全率:
<div align=center>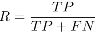 </div>
</div>
<div align=center>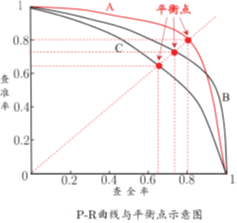 </div>
</div>
如果一条曲线完全包住另一条曲线,则说明另一条曲线性能更优。
如果两条曲线交叉,则用平衡点(BEP)来度量,就是“查准率P=查全率R”时的取值大的更优。不过更常用F1度量:
<div align=center> </div>
</div>
F1的一般形式:
<div align=center> </div>
</div>
ROC曲线:
根据学习器的预测结果对样例排序,并逐个作为正例进行预测,以“假正例率”为横轴,“真正例率”为纵轴可得到ROC曲线,全称“受试者工作特征”。(类似P-R曲线)
AUC(AUC衡量了样本预测的排序质量):
若某个学习器的ROC曲线被另一个学习器的曲线“包住”,则后者性能优于前者;否则如果曲线交叉,可以根据ROC曲线下面积大小进行比较,也即AUC值。
<div align=center>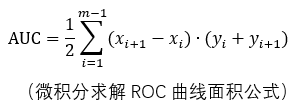 </div>
</div>
现实中不同类型的错误所造成的后果很可能不同,为了权衡不同类型错误所造成的不同损失,可为错误赋予“非均等代价”。
以二分类为例,可根据领域知识设定“代价矩阵”
<div align=center>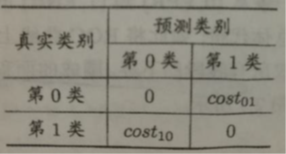 </div>
</div>
在非均等代价下,不再最小化错误次数(错误率直接计算的错误次数),而是最小化“总体代价”,则“代价敏感”错误率相应的为:
<div align=center>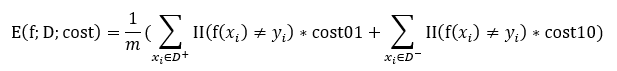 </div>
</div>
 微信
微信 支付宝
支付宝本作品采用 知识共享署名-相同方式共享 4.0 国际许可协议 进行许可。