机器学习 | 模型评估与选择之评估方法
基本概念
错误率:分类错误的样本占样本总数的比例
精度:分类正确的样本占样本总数的比例,即精度=1-错误率。
过拟合:由于学习能力过于强大,以至于把训练样本所包含的不太一般的特性都学到了。
欠拟合:由于学习能力太低下,以至于把训练样本所包含一般的特性没学好。
对数据集D进行适当的处理,从中产生训练集S和测试集T。
<div align=center> </div>
</div>
<div align=center> </div>
</div>
留一法:与交叉验证法相比,省去第五步,每个样本就是一个最小的子集,不可分,可以省略随机划分数据集D,相对准确(不一定),而造成数据模型的计算开销过于庞大难以忍受。
缺陷:留出法和交叉验证法都受训练样本规模不同而导致的估计偏差,留一法受训练样本规模变化的影响较小,但计算复杂度又太高了。
自助法:采用自助采样法为基础,在给定的m个样本的数据集D中,进行有放回的采样,得到训练集D'; ,D\D';用做测试集,重复执行m次,取平均值。(\:表示集合减法)
结果:数据集D中会有一部分样本在训练集D';多次出现,而另一部分的样本不出现,做个简单的估计,样本在m次 采样中始终不被采到的概率是 ,取极限得到
,取极限得到
<div align=center>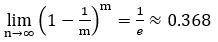 </div>
</div>
所以说,初始数据集D中约有36.8%的样本没出现在采集样本D'中。
自助法在数据集较小,难以划分训练/测试集时很有用。在初始化数据足够,留出法和交叉验证法更常用。
文章目录
 微信
微信 支付宝
支付宝本作品采用 知识共享署名-相同方式共享 4.0 国际许可协议 进行许可。