机器学习 | 线性回归模型拟合bodyfat数据代码实现及泛化误差评估
线性回归模型来拟合bodyfat数据,数据集介绍可阅读:https://www.mathworks.com/help/nnet/examples/body-fat-estimation.html
在matlab中,在命令行中输入[X,Y] = bodyfat_dataset; 即可获得一个拥有13个属性,252个样本的数据集。使用前200个样本来获得模型,并写出你所获得的模型。使用后52个样本做测试,汇报你所获得的泛化误差。(数据集matX,matY,可在文末下载,不用去matlab上获取)
线性模型
<div align=center>f(xi)=w1x1+ w2x2+ w3x3+ w4x4+ w5x5+ w6x6+ w7*x7+
w8x8+ w9x9+ w10x10+ w11x11+ w12x12+ w13x13+ b</div>
原点数据和拟合的线:
<div align=center>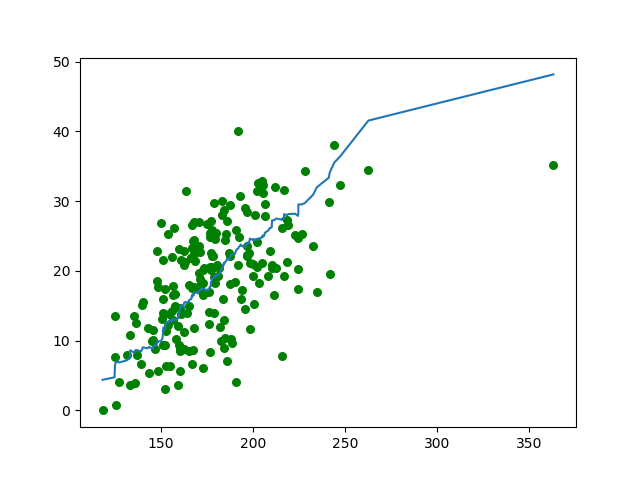 </div>
</div>
代码实现
# 导入numpy包
from numpy import *
# 导入数据,可根据储存的文件结构读取
def loadDataSet(xMatfileName,yMatfileName):
# 每读一行的长度,split('\t')表示以Tab进行分隔
numxLine=len(open(xMatfileName).readline().split('\t'))
numyLine=len(open(yMatfileName).readline().split('\t'))
# x:dataMat ,y: labelMat
labelMat=[];dataMat=[]
# 打开文件
xfr=open(xMatfileName)
# 将数据分割读到labelMat中
for xline in xfr.readlines():
# 定义临时list
xlineArr=[]
# strip()去掉头尾空格,以Tab进行分隔
xcurline=xline.strip().split('\t')
# 处理每一行数据
for i in range(numxLine):
# 将xcurline中的数据转成浮点数
xlineArr.append(float(xcurline[i]))
# 将模型中的b吸收到x中
xlineArr.append(1)
# 转存到dataMat中
dataMat.append(xlineArr)
# 获取dataMat的长度
index=len(dataMat)
# 与x(dataMat)的读取差不多
yfr=open(yMatfileName)
for yline in yfr.readlines():
ylineArr=[]
ycurline=yline.strip().split('\t')
for k in range(numyLine):
ylineArr.append(float(ycurline[k]))
labelMat.append(ylineArr)
# 返回x,y的值列表
return dataMat,labelMat
# 求解w*和b的值
def standRegres(xArr,yArr):
# 转化成矩阵
xMat=mat(xArr)
yMat=mat(yArr)
# 求x的转置与x的乘积
xTx=xMat.T*xMat
# 计算行列式是否为0,判断是否为奇异矩阵.
if linalg.det(xTx)==0.0:
print("该矩阵为奇异矩阵,无法求逆!")
return
# 求解w*和b的矩阵
ws=xTx.I * (xMat.T*yMat)
return ws
# 计算均方误差(测量误差)约等于泛化误差
def GeneralizationError(yHat,ytestMat):
# (验证组的预测值-标记值)的平方,然后求和,除以验证的个数
return sum(square(yHat-ytestMat))/ytestMat.shape[0]
from numpy import *
# 导入matX,matY数据集
xArr,yArr=loadDataSet('matX','matY')
# 取200个为数据集
tran_xArr=xArr[0:200]
tran_yArr=yArr[0:200]
# 取剩下53为测试集
test_xArr=xArr[200:]
test_yArr=yArr[200:]
# 求解w*和b的矩阵,前13个是w0,w1….w12,
# 最后一个是吸收进x矩阵的b取值
ws=standRegres(tran_xArr,tran_yArr)
print("w/b(最后一位是b):\n",ws)
# 训练集
xMat=mat(tran_xArr)
yMat=mat(tran_yArr)
yHat=xMat*ws
# 测试集
xtestMat=mat(test_xArr)
ytestMat=mat(test_yArr)
# 预测的模型的预测值
ytestHat=xtestMat*ws
# 求解泛化误差
print("Mse:",GeneralizationError(ytestHat,ytestMat))
# 画回归模型图
import matplotlib
import matplotlib.pyplot as plt
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.scatter(xMat[:,1].flatten().A[0],yMat[:,0].flatten().A[0],30,'green')
xCopy=xMat.copy()
# 对x进行整理排序
xCopy.sort(0)
yHat=xCopy*ws
ax.plot(xCopy[:,1],yHat)
plt.show()
fig.show()其实如果用sklearn框架会更简单,不必手撸拟合函数,直接调用,美滋滋.........哭唧唧
bodyfat数据集(百度云):https://pan.baidu.com/s/1BVZUxPdbe0FJ2fsOlxZdqA
文章目录
 微信
微信 支付宝
支付宝本作品采用 知识共享署名-相同方式共享 4.0 国际许可协议 进行许可。
新鸟上道....请多多指教