机器学习 | 决策树 实践篇
问题
基于表中编号为1、2、3、6、7、9、10、14、15、16、17的11个样本的色泽、根蒂、敲声、文理特性构建决策树,编程实现。
<div align=center>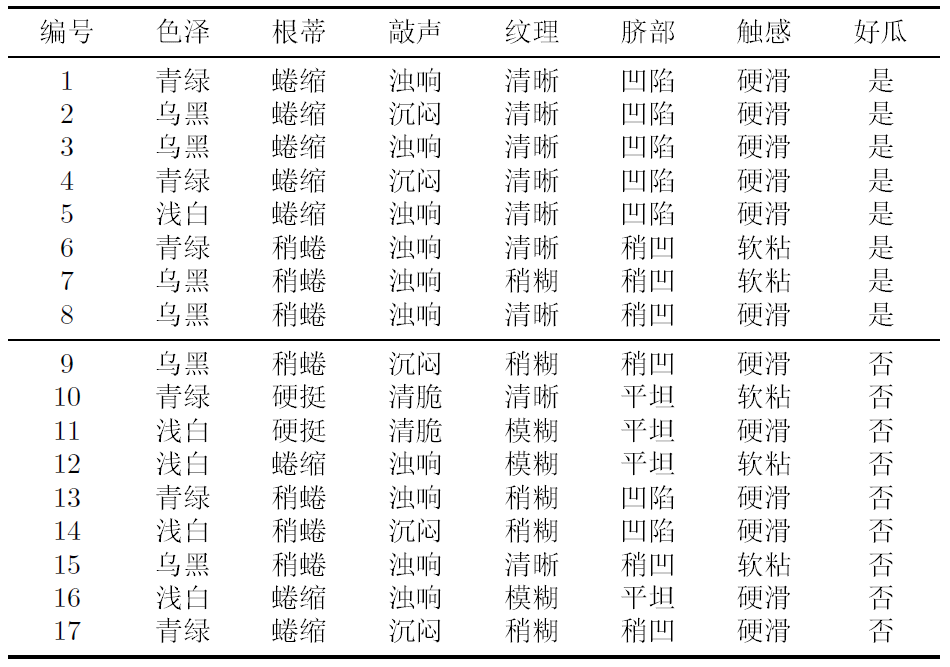 </div>
</div>
代码实现
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Sun Oct 14 21:45:45 2018
@author: harley
青绿:0,乌黑:1,浅白:2
蜷缩:0,稍蜷:1,硬挺:2
浊响:0,沈闷:1,清脆:2
清晰:0,稍糊:1,模糊:2
好瓜:0,坏瓜:1
"""
from sklearn import tree
import numpy as np
import graphviz
# 数据集
dataSet1 = [[0,0,0,0],
[0,0,0,0],
[1,0,0,0],
[0,1,0,0],
[1,1,0,1],
[1,1,1,1],
[0,2,2,0],
[2,1,1,1],
[1,1,0,0],
[2,0,0,2],
[0,0,1,1]]
labels1 = [0,0,0,0,0,1,1,1,1,1,1]
feature_names=['色泽','根蒂','敲声','纹理']
target_names=['好瓜','坏瓜']
# 利用sklearn中的决策树
clf= tree.DecisionTreeClassifier(criterion='entropy')
# 传入数据
clf=clf.fit(dataSet1,labels1)
# 创建树形图 feature_names表示属性,class_names表示种类名,
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=feature_names,
class_names=target_names,
filled=True, rounded=True,
special_characters=True)
# 保存
graph = graphviz.Source(dot_data)
# 即时查看图片
graph.view()利用graphviz制图
<div align=center>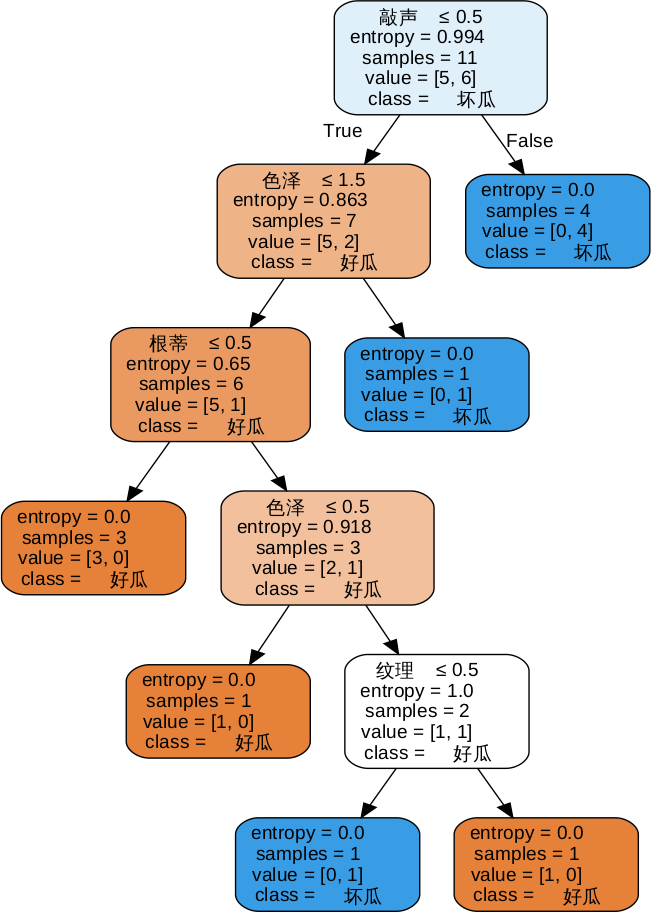 </div>
</div>
文章目录
文章目录
 微信
微信 支付宝
支付宝本作品采用 知识共享署名-相同方式共享 4.0 国际许可协议 进行许可。
Hi! Would you mind if I share your blog with my facebook group?
There's a lot of folks that I think would really enjoy
your content. Please let me know. Cheers
可以分享
但是麻烦备注好文章来源处和作者
哦哦哦啦啦啦